RCNN
1. 후보영역 추출
2. 고정된 사이즈로 wraping
3. 모델에 넣고,
selective search
: 이미지에 색깔, 질감 (texture), shape등을 활용해서,
이미지를 무수히 많은 작은 영역으로 나눈다음, 이 영역을 점차 통합해 나가는 과정을 거친다.
통합된 최종결과를 후보영역으로 사용한다.
selective search는 이미지 한장에 대해서 2000개의 roi를 추출한다.
추출된 후보영역을 동일한 사이즈로 warping ( cnn의 fc는 입력사이즈가 고정되어있다)
5-1)
cnn을 통해 나온 feature를 svm에 넣어 분류를 진행한다.
input : 2000x4096 features
output : class(C+1), confidence scores
5-2)
selective search를 통해 나온 bouding box 가 매우 러프 하므로,
ss는 객체가 존재할만한 위치를 를 정확하게 예측해주지 않는다. 대충 예측함,
따라서 이 위치를 미세조정해주는 regresseer을 학습해야한다.
이 regressser 은
bb의 중심점을 gt의 중심점으로 옮기고,
bb의 w,h를 gt의 w,h로 옮긴다.
2.3 Training
# AlexNext (feature extraction)
- Domain Specific finetuning
- finenuting 진행시 dataset 구성을
iou > 0.5 positive samples
iou < 0.5 negative sampes
한 배치는 positive sampe 32, negative samples 96 로 구성된다.
# Linear SVM (predict class)
- dataset 구성
gt : positive samples,
IoU < 0.3 : negative samples
한 배치에 positive 32, negative samples 96 - Hard negative mining
hard negative : false positive
모델이 배경으로 식별하기 어려운 샘플들을 강제로 다음 배치의 negative sampel로 mining 하는 방법
수행하는 이유? : 2000 의 제안된 roi 들 중 객체를 포함하는 region은 매우 적고, 대부분 배경이다.
그래서 negative region 을 quality 있게 포함하기 위해 해당 작업 수행
# BB regressor
- dataset 구성 - iou > 0.6 positive samples (negative samples 는 bb가 없으므로)
2.4 단점 (r-cnn)
1. 2000개의 region 을 각 cnn에 통과시킴 (cnn을 2000번이나! 매우느림)
2. 객체크기를 고정된 사이즈로 warping 하므로 객체정보가 손실된다.
3. CNN, SVM,BB regressor을 따로 학습하므로 -> e2e가아님 구조적인 측면에서 한계점이 존재.
SPP-NET
효과 : 컨볼루션이 1번이다!! / 강제 warping을 spartial pyramid pooling을 통해 해결 !
- 입력 이미지에 컨볼루션을 수행하여 나온 feature map에서 2000개의 region 을 뽑아 낸다. -- 추후 정리
- Spatial Pyramid Pooling Layer (warping 대신 수행하는 부분 ) 설명
# Spatial Pyramid Pooling

비닝한다.
타겟 사이즈 피라미드 사이즈가 (2x2)면 입력 이미지를 사이즈에 맞게 나누고,
1개의 bin에서 1개의 특징을 추출한다 (max pooling, average pool을 하던 )
: 효과 input사이즈 (roi)에 상관없이 고정된 개수의 feature를 추출 할 수 있다.
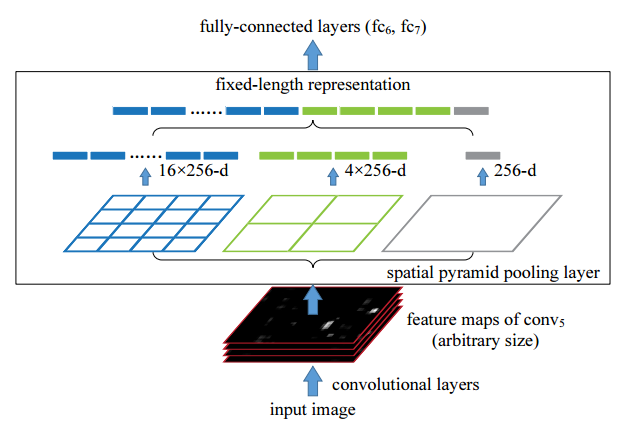
# 256은 filter 수
Fast R-CNN
" RoI Pooling " : 고정된 사이즈의 features vector
VGG16을 사용
이미지에서 VGG16 네트워크를 사용해서 feature map을 얻음
feature map 에서 roi를 뽑아내야한다.
feature map에 selective search(=원본이미지의 색, 텍스쳐를 통한 그룹핑) 를 할 수 없음!
따라서 selective search는 원본이미지에서 수행해서 roi 영역을 뽑아내고(=bb) 대응되는 feature map에서 feature을 가져온다.
근데 문제가 있음,
cnn통과했을때, feature map이 convolution 때문에 줄어드는 경우도 있음, 이때는 roi사이즈를 조절 해줘야함
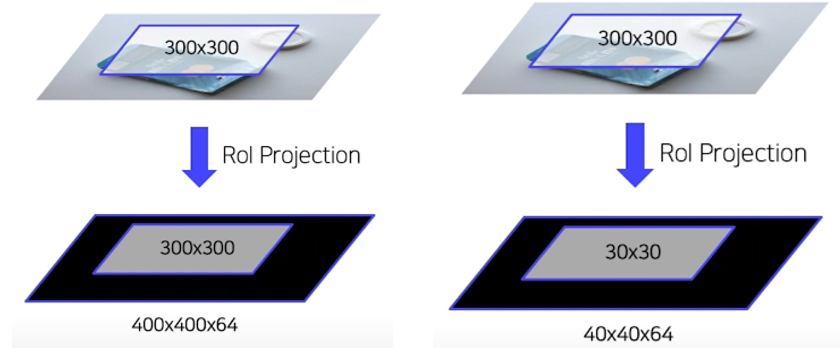
Roi Pooling 을 통해 일정한 크기의 feature 추출
- 고정된 vector을 얻기 위한 과정
target size 가 7x7 1개이다.