1. 'Add': 잔차 연결 (Residual Connection)
핵심은 **'정보의 길을 터주는 것'**입니다. 고속도로의 '직통 차선'을 만들어주는 것과 같습니다.
핵심 내용
- 서브-레이어에 **들어가기 전의 입력(x)**을 서브-레이어를 **통과한 후의 출력(SubLayer(x))**에 그대로 더해주는 과정입니다.
- 이를 통해 정보가 여러 레이어를 거치면서 소실되거나 변형되는 것을 막고, 원본 정보가 다음 레이어까지 직접 전달될 수 있도록 합니다.
반드시 알아야 할 내용 (학습 안정화 원리)
- 그래디언트 소실(Gradient Vanishing) 문제 완화: 딥러닝 모델은 깊어질수록 역전파 과정에서 그래디언트(기울기)가 점점 작아져 학습이 잘 안되는 문제가 발생합니다.
- 하지만 잔차 연결이 있으면, 그래디언트가 이 '직통 차선'을 통해 이전 레이어로 잘 전달될 수 있습니다. 즉, 기울기가 0에 가까워지는 것을 방지하여 깊은 네트워크도 안정적으로 학습할 수 있게 됩니다.
- 학습의 초점 변화: 모델이 H(x)라는 복잡한 변환을 학습하는 대신, 입력 x는 그대로 두고 변화량, 즉 잔차(Residual)인 F(x) = H(x) - x만 학습하도록 유도합니다. 변화량만 학습하는 것이 더 쉽고 효율적입니다.
수식으로 이해하기
잔차 연결은 다음과 같이 간단한 덧셈으로 표현할 수 있습니다. 수식 복사가 편하도록 Markdown으로 작성했습니다.
Residual_Output = x + SubLayer(x)
- x: 서브-레이어(어텐션 또는 피드 포워드)의 입력
- SubLayer(x): 서브-레이어의 출력
2. 'Norm': 레이어 정규화 (Layer Normalization)
핵심은 **'데이터를 길들이는 것'**입니다. 각 레이어의 출력을 "정돈된" 형태로 만들어 다음 레이어로 전달하는 과정입니다.
핵심 내용
- 각 데이터 샘플(문장) 내의 모든 특성(단어 벡터의 각 차원)들의 평균을 0, 분산을 1로 만들어주는 정규화 기법입니다.
- 이렇게 데이터의 분포를 일정하게 유지시켜 학습 과정을 안정화하고 속도를 향상시킵니다.
반드시 알아야 할 내용 (학습 안정화 원리)
- 내부 공변량 변화(Internal Covariate Shift) 문제 해결: 각 레이어를 지날 때마다 데이터의 분포가 달라지면 모델이 학습하기 어려워집니다. 레이어 정규화는 각 레이어의 입력 분포를 일정하게 유지시켜 이 문제를 해결합니다.
- 그래디언트 폭주/소실 완화: 정규화를 통해 데이터 값이 너무 크거나 작아지는 것을 방지하여, 그래디언트가 폭주하거나 소실될 위험을 줄여줍니다.
- 학습 속도 향상: 데이터 분포가 안정적이므로, 모델이 더 빠르고 효율적으로 최적의 가중치를 찾아갈 수 있습니다.
수식으로 이해하기
레이어 정규화는 다음과 같은 단계로 이루어집니다.
LayerNorm(x) = γ * ( (x - μ) / sqrt(σ² + ε) ) + β
- μ (평균) 계산: 한 데이터 샘플 x 내 모든 특성 값들의 평균을 구합니다.
- σ² (분산) 계산: 한 데이터 샘플 x 내 모든 특성 값들의 분산을 구합니다.
- 정규화: 평균을 빼고 표준편차(sqrt(σ² + ε))로 나누어, 평균 0, 분산 1인 분포로 만듭니다. (ε은 분모가 0이 되는 것을 막는 아주 작은 값입니다.)
- 크기 조절 및 이동: 학습 가능한 파라미터 γ(감마, 크기 조절)와 β(베타, 이동)를 곱하고 더해줍니다. 이를 통해 모델이 정규화된 분포를 유연하게 조절할 수 있게 됩니다.
3. 'Add & Norm' 종합: 왜 이 순서일까?
트랜스포머에서는 이 두 과정을 LayerNorm(x + SubLayer(x)) 순서로 적용합니다.
- Add: 먼저 입력 x와 서브-레이어의 출력 SubLayer(x)를 더합니다. (정보 보존)
- Norm: 더해진 결과값의 분포를 안정적으로 정규화합니다. (학습 안정화)
이 구조 덕분에 트랜스포머는 수십, 수백 개의 레이어를 쌓아도 안정적으로 학습하고 뛰어난 성능을 낼 수 있는 것입니다.
헷갈리기 쉬운 내용: 레이어 정규화 vs. 배치 정규화
| 구분 | 레이어 정규화 (Layer Normalization) | 배치 정규화 (Batch Normalization) |
| 정규화 대상 | 하나의 데이터 샘플 내 모든 특성 | 미니배치 내 모든 데이터의 하나의 특성 |
| 주 사용 분야 | NLP (RNN, 트랜스포머) | Computer Vision (CNN) |
| 장점 | 배치 크기에 영향을 받지 않아 작은 배치나 가변 길이 시퀀스에 유리 | 큰 배치 크기에서 효과적이며, 규제(regularization) 효과가 있음 |
트랜스포머에서 배치 정규화 대신 레이어 정규화를 쓰는 이유는, 문장의 길이는 샘플마다 다른데, 배치 정규화는 고정된 크기의 특성 차원에 대해 연산하기 때문에 가변 길이 시퀀스를 다루기 어렵기 때문입니다.
✍️ 주관식 예상 문제
문제: 트랜스포머 모델에서 'Add & Norm' 구조가 깊은 네트워크의 학습을 안정시키는 원리를 **잔차 연결(Add)**과 **레이어 정규화(Norm)**의 역할을 각각 구분하여 서술하시오. 또한, 트랜스포머에서 배치 정규화 대신 레이어 정규화를 사용하는 이유를 설명하시오.
모범 답안 예시:
트랜스포머의 'Add & Norm'은 잔차 연결과 레이어 정규화를 통해 학습을 안정시킨다.
1. 잔차 연결(Add)의 역할: 서브-레이어의 입력과 출력을 더함으로써, 역전파 시 그래디언트가 소실되지 않고 이전 레이어로 직접 전달될 수 있는 경로를 제공한다. 이는 깊은 네트워크에서 발생하는 그래디언트 소실 문제를 완화하여 안정적인 학습을 가능하게 한다.
2. 레이어 정규화(Norm)의 역할: 각 레이어의 출력값 분포를 평균 0, 분산 1로 일정하게 유지시킨다. 이는 학습 과정에서 데이터 분포가 급격히 변하는 내부 공변량 변화를 막아주어, 학습을 안정화하고 속도를 높인다.
3. 레이어 정규화 사용 이유: 문장과 같은 시퀀스 데이터는 길이가 가변적이다. 배치 정규화는 배치 단위로 특성의 통계를 계산하므로 가변 길이 시퀀스에 적용하기 어렵지만, 레이어 정규화는 개별 데이터 샘플 내에서 정규화를 수행하므로 배치 크기나 시퀀스 길이에 영향을 받지 않아 트랜스포머에 더 적합하다.
그레디언트가 소실되지 않는 이유.
## 핵심 원리: '덧셈'의 미분은 '1'을 남긴다
수학에서 y = f(x) + x 라는 식이 있을 때, y를 x로 미분하면 어떻게 될까요?
바로 이 + 1이 핵심입니다. 이 간단한 원리가 딥러닝의 역전파 과정에 적용되어 그래디언트 소실을 막아줍니다.
## 수식으로 보는 그래디언트 흐름
이제 실제 딥러닝 모델의 역전파 과정에 대입해 보겠습니다.
1. 잔차 연결이 없을 때 (그래디언트 소실 발생)
일반적인 딥러닝 레이어는 입력 x가 레이어 F를 통과해 y = F(x)가 됩니다. 역전파 시, 최종 손실(Loss) L에 대한 x의 그래디언트는 연쇄 법칙(Chain Rule)에 따라 다음과 같이 계산됩니다.
만약 네트워크가 깊어져서 ... -> x_i -> x_{i+1} -> ... 와 같이 여러 레이어를 통과한다면, 그래디언트는 계속해서 곱해집니다.
여기서 각 레이어의 미분 값인 ∂x_{j+1}/∂x_j가 1보다 작은 값(예: 0.5)이라면, 이 값들이 계속 곱해지면서 그래디언트는 0에 가깝게 사라져 버립니다. 이것이 바로 **그래디언트 소실(Vanishing Gradient)**입니다.
2. 잔차 연결이 있을 때 (그래디언트 소실 완화)
잔차 연결이 있는 레이어의 출력은 y = F(x) + x 입니다. 이제 역전파를 계산해 봅시다.
여기서 위에서 본 미분 공식을 적용하면 ∂y/∂x는 (∂F(x)/∂x + 1)이 됩니다. 따라서,
이 식이 바로 그래디언트 소실을 막아주는 열쇠입니다.
## '+1'의 의미: 그래디언트 고속도로 🛣️
위 수식을 다시 살펴보겠습니다.
- '+1'의 효과: 설령 레이어 F를 통과하는 그래디언트(∂F(x)/∂x 부분)가 복잡한 연산 때문에 0에 가까워지더라도, +1 항 덕분에 상위 레이어의 그래디언트(∂L/∂y)가 아무런 방해 없이 그대로 하위 레이어로 전달됩니다.
- 그래디언트 고속도로: 즉, 잔차 연결은 그래디언트가 복잡한 길(레이어 F)을 거치지 않고 직통으로 달릴 수 있는 '고속도로'를 만들어주는 셈입니다. 이 고속도로 덕분에 아무리 네트워크가 깊어져도 그래디언트가 완전히 소실될 위험이 크게 줄어들어 안정적인 학습이 가능해집니다.
## ✍️ 주관식 대비 핵심 정리
질문: 잔차 연결(Residual Connection)이 그래디언트 소실 문제를 완화하는 원리를 수식의 관점에서 설명하시오.
모범 답안 예시:
잔차 연결의 순전파 수식은 y = F(x) + x로 표현됩니다. 이를 손실 함수 L에 대해 x로 편미분하여 역전파 그래디언트를 구하면 연쇄 법칙에 의해 ∂L/∂x = (∂L/∂y) * (∂y/∂x)가 됩니다. 여기서 ∂y/∂x는 (∂F(x)/∂x + 1)로 계산됩니다.
최종 그래디언트 수식은 ∂L/∂x = (∂L/∂y) * (∂F(x)/∂x + 1)이 되는데, 이 식의 +1 항이 핵심적인 역할을 합니다. 이 +1 덕분에, 레이어 F(x)를 통과하는 그래디언트 ∂F(x)/∂x가 0에 가까워지더라도 상위 레이어의 그래디언트 ∂L/∂y가 소실되지 않고 x로 직접 전달될 수 있습니다. 따라서 깊은 네트워크에서도 그래디언트가 효과적으로 전파되어 학습이 안정적으로 이루어집니다.
FFN 이란?
FFN(Feed-Forward Network)은 어텐션 레이어가 모아온 정보들을 '개별적으로, 그리고 더 깊게 처리하는 전문가' 역할을 합니다.
Self-Attention이 문장 전체를 보고 각 단어의 '관계'와 '중요도'를 파악해서 정보를 융합하는 단계라면, FFN은 이렇게 융합된 정보를 각 단어 위치(position)마다 하나씩 개별적으로 받아 더욱 복잡한 비선형(non-linear) 변환을 통해 고차원적인 특성을 추출하는 단계입니다.
쉽게 비유하자면,
- Self-Attention: 회의에서 모든 팀원들의 의견을 듣고 종합하여 각자에게 "이 프로젝트에서 당신의 역할은 이러이러한 것입니다"라고 재정의해주는 과정. (정보의 융합 및 관계 파악)
- FFN: 역할을 부여받은 각 팀원이 자기 자리로 돌아가 자신에게 주어진 정보를 가지고 더 깊이 생각하고 발전시키는 과정. (개별 정보의 심화 처리)
## FFN의 핵심 내용 및 역할
1. 비선형성(Non-Linearity) 추가
- 핵심 내용: Self-Attention 메커니즘은 가중합(weighted sum)을 기반으로 하므로, 그 자체만으로는 선형(linear) 변환에 가깝습니다. 모델이 언어의 복잡하고 비선형적인 패턴(예: 단어의 중의성, 복잡한 문법 구조)을 학습하려면 비선형 함수가 필수적입니다.
- 역할: FFN은 ReLU와 같은 비선형 활성화 함수를 사용하여 모델의 표현력을 크게 높여줍니다. 이것이 없다면 트랜스포머는 여러 층을 쌓아도 결국 하나의 거대한 선형 변환과 다를 바 없게 되어 성능이 크게 저하됩니다.
2. 위치별(Position-wise) 연산
- 핵심 내용: FFN은 문장의 모든 단어에 동일한 가중치(W1, W2)를 공유하지만, 각 단어 위치마다 독립적으로 적용됩니다.
- 역할: 이는 어텐션을 통해 문맥 정보가 풍부해진 각 단어 벡터를 개별적으로, 하지만 일관된 방식으로 처리하여 표현을 더욱 정교하게 만듭니다. CNN의 필터가 이미지의 모든 위치에 동일하게 적용되는 것과 유사한 원리입니다.
## 수식으로 이해하기
FFN의 구조는 매우 간단합니다. 2개의 선형 변환(Linear Layer) 사이에 ReLU 활성화 함수가 있는 형태입니다.
어텐션 서브-레이어의 출력 x가 FFN에 입력되었을 때의 계산 과정은 다음과 같습니다.
FFN(x) = max(0, xW₁ + b₁)W₂ + b₂
- xW₁ + b₁: 입력 x를 첫 번째 선형 레이어(가중치 W₁, 편향 b₁)를 통과시켜 차원을 확장합니다. (예: 512차원 -> 2048차원)
- max(0, ...): ReLU 활성화 함수를 적용하여 비선형성을 추가합니다.
- ...W₂ + b₂: ReLU의 출력을 두 번째 선형 레이어(가중치 W₂, 편향 b₂)를 통과시켜 다시 원래 차원으로 축소합니다. (예: 2048차원 -> 512차원)
이 "차원 확장 -> 비선형 변환 -> 차원 축소" 구조를 통해 모델은 더 풍부한 특징을 학습할 수 있는 공간을 잠시 확보했다가, 다시 필요한 정보만 압축하여 다음 레이어로 전달합니다.
## 헷갈리기 쉬운 내용
- Q: FFN이 모든 단어에 똑같이 적용되면, 각 단어의 개별적인 의미를 어떻게 처리하나요?
- A: FFN에 들어가는 입력 x는 이미 Self-Attention을 거친 후의 벡터입니다. 즉, x 안에는 이미 해당 단어의 원래 의미뿐만 아니라, 문장 전체의 문맥과 다른 단어와의 관계가 모두 풍부하게 녹아있습니다. FFN은 이렇게 문맥이 반영된 개별 벡터를 각각 심화 처리하는 것이므로, 동일한 연산을 적용해도 결과적으로는 각 단어의 고유한 문맥적 의미를 정교하게 만들 수 있습니다.
## ✍️ 주관식 예상 문제
문제: 트랜스포머 모델에서 Self-Attention 서브-레이어 다음에 Position-wise Feed-Forward Network(FFN)가 필요한 이유를 **'비선형성'**과 **'연산 방식'**의 관점에서 서술하시오.
모범 답안 예시:
FFN은 두 가지 주요 이유 때문에 필요하다.
첫째, 비선형성을 추가하기 위함이다. Self-Attention은 주로 선형 변환에 기반하므로, 모델의 표현력을 높이기 위해 ReLU와 같은 비선형 활성화 함수를 포함한 FFN을 사용하여 언어의 복잡한 패턴을 학습할 수 있게 한다.
둘째, 위치별(Position-wise) 연산을 통해 개별 토큰의 표현을 심화하기 위함이다. FFN은 어텐션을 통해 문맥 정보가 풍부해진 각 토큰 벡터에 대해 독립적이지만 동일한 변환을 적용한다. 이를 통해 각 위치의 정보를 개별적으로 더욱 정교하게 가공하여 모델의 전체적인 성능을 향상시킨다.
ffn 코드
import torch
import torch.nn as nn
class PositionwiseFeedForward(nn.Module):
"""
트랜스포머의 Position-wise Feed-Forward Network 구현
"""
def __init__(self, d_model, d_ff, dropout=0.1):
"""
FFN 레이어를 초기화합니다.
Args:
d_model (int): 모델의 입력 및 출력 차원 (임베딩 차원)
d_ff (int): 내부 레이어의 차원 (보통 d_model의 4배)
dropout (float): 드롭아웃 비율
"""
super(PositionwiseFeedForward, self).__init__()
# 첫 번째 선형 레이어 (차원 확장)
# FFN(x) = max(0, xW₁ + b₁)W₂ + b₂ 에서 xW₁ + b₁ 부분
self.linear1 = nn.Linear(d_model, d_ff)
# 두 번째 선형 레이어 (차원 축소)
# ... )W₂ + b₂ 부분
self.linear2 = nn.Linear(d_ff, d_model)
# ReLU 활성화 함수
# max(0, ...) 부분
self.relu = nn.ReLU()
# 드롭아웃 (과적합 방지)
self.dropout = nn.Dropout(p=dropout)
def forward(self, x):
"""
순전파를 정의합니다.
Args:
x (torch.Tensor): 어텐션 서브-레이어의 출력.
(batch_size, seq_len, d_model) 크기.
Returns:
torch.Tensor: FFN을 통과한 후의 텐서.
(batch_size, seq_len, d_model) 크기.
"""
# 1. 첫 번째 선형 레이어 통과 (차원: d_model -> d_ff)
x = self.linear1(x)
# 2. ReLU 활성화 함수 적용
x = self.relu(x)
# 3. 드롭아웃 적용
x = self.dropout(x)
# 4. 두 번째 선형 레이어 통과 (차원: d_ff -> d_model)
x = self.linear2(x)
return x
# --- 모델 하이퍼파라미터 설정 ---
d_model = 512 # 입력 및 출력 차원 (논문 기본값)
d_ff = 2048 # FFN의 내부 은닉층 차원 (d_model * 4)
batch_size = 64 # 배치 크기
seq_len = 100 # 문장 길이
# --- FFN 모델 인스턴스 생성 ---
ffn = PositionwiseFeedForward(d_model, d_ff)
print("FFN 모델 구조:")
print(ffn)
print("-" * 30)
# --- 임의의 입력 데이터 생성 ---
# 실제로는 Self-Attention 레이어의 출력이 이 곳에 들어옵니다.
# (배치 크기, 문장 길이, 모델 차원)
input_tensor = torch.rand(batch_size, seq_len, d_model)
print(f"입력 텐서의 크기: {input_tensor.shape}")
# --- FFN 순전파 실행 ---
output_tensor = ffn(input_tensor)
print(f"출력 텐서의 크기: {output_tensor.shape}")
# --- 결과 확인 ---
# 입력과 출력의 텐서 크기가 동일한 것을 확인할 수 있습니다.
# 이는 다음 'Add & Norm' 레이어에서 잔차 연결을 하기 위해 필수적입니다.
assert input_tensor.shape == output_tensor.shape
print("\n입력과 출력의 크기가 동일함을 확인했습니다.")
Scaled Dot-Product Attention의 계산 과정에서, Dot Product 결과를 키(Key) 벡터의 차원(dk
)의 제곱근으로 나누는 이유는?
문제에 대한 가장 적절한 답은 "Dot-Product의 결과값이 너무 커져 Softmax 함수가 포화(saturate)되고, 이로 인해 그래디언트가 소실되는 것을 방지하기 위해서" 입니다.
## 지식 정리: Scaled Dot-Product Attention의 모든 것
Step 1: 어텐션의 기본 - "그래서 뭘 하려는 건데?"
어텐션의 목표는 **"이 문장에서 현재 단어와 가장 관련이 깊은 단어는 무엇인가?"**를 알아내는 것입니다. 이를 위해 Query, Key, Value (Q, K, V) 라는 세 가지 개념을 사용합니다.
- Query (Q): 현재 내가 주목하고 있는 단어의 벡터. (예: "나는 그 동물을 좋아해" 에서 '그' 라는 단어)
- Key (K): 문장 내 다른 모든 단어의 벡터. Q와 비교 대상이 됩니다. (예: '나는', '동물을', '좋아해')
- Value (V): 문장 내 다른 모든 단어의 벡터. Key와 짝을 이룹니다. 최종 결과에 반영될 정보값입니다.
Step 2: Dot-Product (내적) - "관련성을 어떻게 계산하는데?"
Query '그'가 다른 단어들과 얼마나 관련 있는지 알아보기 위해, Q 벡터와 모든 K 벡터를 각각 Dot-Product(내적) 연산합니다. 벡터의 내적은 두 벡터가 얼마나 유사한 방향을 가리키는지를 나타내므로, 이는 곧 유사도(Similarity) 점수가 됩니다.
Similarity Score = Query · Key
Step 3: The PROBLEM - "차원이 커지면 왜 문제가 되는데?" 💥
여기가 핵심입니다. 트랜스포머에서 사용하는 벡터의 차원 d_k는 보통 64, 128처럼 꽤 큰 값입니다.
- 통계적 함정: 평균이 0이고 분산이 1인 두 벡터를 내적하면, 그 결과값의 분산은 벡터의 차원 d_k가 됩니다. 즉, 차원 d_k가 커질수록 내적의 결과값(유사도 점수)들이 0을 기준으로 훨씬 더 크거나 작은 값들을 갖게 됩니다. (분산이 커지므로 값이 퍼짐)
- Softmax의 약점: 어텐션 점수를 확률처럼 만들기 위해 Softmax 함수를 사용합니다. 그런데 Softmax 함수는 입력값이 너무 크거나 작아지면 문제가 생깁니다. 아래 그래프를 보세요.
- 입력값(x축)이 0 주변일 때는 그래프의 기울기가 완만하지만, +5나 -5처럼 절댓값이 커지면 기울기가 거의 0에 가까워집니다. 이 영역을 **포화 영역(Saturation Region)**이라고 합니다.
- 딥러닝의 학습은 '기울기(Gradient)'를 통해 이루어지는데, 기울기가 0이 되어버리면 역전파 과정에서 전달할 정보가 사라집니다. 이것이 바로 그래디언트 소실(Vanishing Gradient) 문제입니다.
- 논리의 완성: d_k가 크다 → 내적 값이 매우 커진다 → Softmax의 포화 영역으로 들어간다 → 기울기가 0이 된다 → 학습이 안 된다!
Step 4: The SOLUTION - "왜 하필
인가?" 💡
통계학에서 분산이 σ²인 데이터의 표준편차는 σ입니다. 데이터를 표준편차로 나누면 분산이 1이 됩니다.
- 위에서 내적 값의 분산이 d_k라고 했습니다. 그렇다면 표준편차는 입니다.
- 따라서, 분산이 d_k인 내적 값들을 그것의 표준편차인 $\sqrt{d_k}$로 나누어주면, 결과적으로 분산이 1이 되도록 스케일을 조절할 수 있습니다.
- 이렇게 스케일이 조절된 값들은 Softmax 함수가 좋아하는 '완만한' 영역에 머무를 가능성이 커지고, 그래디언트가 소실되지 않아 안정적인 학습이 가능해집니다.
이것이 바로 'Scaled' Dot-Product Attention이라는 이름이 붙은 이유입니다.
최종 계산식
이 모든 과정을 하나의 수식으로 표현하면 다음과 같습니다.
Attention 수식이해
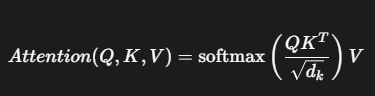
평균 0, 분산 1인 두 벡터를 내적하면, 그 결과의 분산은 벡터의 차원 d_k가 됩니다.
## 비유로 이해하기: 주사위 굴리기 🎲
- 상황 1: 주사위 1개 굴리기
- 결과값은 1에서 6 사이입니다. 결과의 변동성(분산)이 크지 않죠.
- 상황 2: 주사위 64개 동시에 굴려서 나온 눈을 모두 더하기
- 결과값은 최소 64(모두 1)에서 최대 384(모두 6)까지 나옵니다.
- 1개를 굴릴 때보다 결과의 변동폭(분산)이 엄청나게 커졌습니다.
Dot-Product(내적) 연산이 바로 이 '주사위 64개를 동시에 굴려 더하는' 행위와 같습니다.
- 벡터의 각 차원 값: 주사위 하나하나의 결과 (작은 불확실성)
- 벡터의 차원 d_k: 주사위의 개수 (여기서는 64개)
- 내적의 최종 결과: 모든 주사위 눈의 합 (엄청나게 커진 불확실성)
'통계적 함정'이란, 우리가 모델 성능을 높이려고 벡터의 차원(d_k, 즉 주사위 개수)을 늘렸을 뿐인데, 의도치 않게 내적의 결과값이 폭발적으로 변하게 되는 현상을 말하는 것입니다.
## 수식으로 증명하기: 분산의 덧셈 법칙
조금 더 수학적으로 왜 내적 값의 분산이 d_k가 되는지 증명해 보겠습니다.
1. 기본 가정
- Query 벡터 q와 Key 벡터 k가 있습니다. 두 벡터의 차원은 d_k입니다.
- 각 벡터의 요소(q_i, k_i)들은 서로 독립이며, 평균()이 0이고 분산()이 1인 분포를 따른다고 가정합니다. (이는 일반적인 데이터 정규화 가정입니다.)
2. 내적(Dot-Product)의 정의
- q와 k의 내적은 각 요소끼리의 곱을 모두 더한 값입니다.
3. 분산 계산
우리가 구하고 싶은 것은 Var(q · k) 입니다.
- 먼저, 곱셈의 분산 Var(q_i k_i)을 구해봅시다.
- E[q_i k_i] = E[q_i]E[k_i] = 0 \times 0 = 0 (서로 독립이므로 기댓값 분리 가능)
- E[(q_i k_i)^2] = E[q_i^2 k_i^2] = E[q_i^2]E[k_i^2]
- 분산 공식 Var(X) = E[X^2] - (E[X])^2 에 따라 E[X^2] = Var(X) + (E[X])^2 입니다.
- E[q_i^2] = Var(q_i) + (E[q_i])^2 = 1 + 0^2 = 1 입니다. (E[k_i^2]도 동일)
- 따라서 E[(q_i k_i)^2] = 1 \times 1 = 1 입니다.
- 결론적으로 Var(q_i k_i) = E[(q_i k_i)^2] - (E[q_i k_i])^2 = 1 - 0^2 = 1 입니다.
- 이제 전체 내적의 분산을 구해봅시다. 서로 독립인 확률 변수들의 합의 분산은 각 변수의 분산의 합과 같습니다.
- 위에서 Var(q_i k_i)가 1이라고 구했으므로, 1을 d_k번 더하게 됩니다.
증명 완료: 평균 0, 분산 1인 두 벡터를 내적하면, 그 결과의 분산은 벡터의 차원 d_k가 됩니다.
문제: 트랜스포머의 Scaled Dot-Product Attention에서 스케일링 팩터(
)를 사용하는 이유를 (1) 스케일링이 없을 때 발생하는 문제점과 (2) 해당 팩터를 사용했을 때의 해결 원리로 나누어 서술하시오.
모범 답안 예시:
(1) 문제점: 스케일링이 없다면, Key 벡터의 차원 d_k가 커질수록 Query와 Key의 내적 값의 분산도 커지게 된다. 이처럼 절댓값이 큰 값들이 Softmax 함수에 입력될 경우, 함수가 포화 영역(saturation region)에 들어가게 되어 그래디언트(기울기)가 0에 가까워지는 그래디언트 소실 문제가 발생하여 모델의 학습이 불안정해진다.
(2) 해결 원리: 내적 값의 분산이 d_k이므로, 이를 표준편차인 $\sqrt{d_k}$로 나누어주면 결과값의 분산을 1로 만들 수 있다. 이렇게 스케일링된 값은 Softmax 함수가 그래디언트를 효과적으로 계산할 수 있는 범위 내에 존재할 가능성이 높아지므로, 그래디언트 소실 문제를 완화하고 깊은 네트워크의 학습을 안정시키는 효과를 가져온다.
'시험 > 기본개념' 카테고리의 다른 글
| ai 시스템 모니터링 및 자동화 (0) | 2025.09.03 |
|---|---|
| attention sink (0) | 2025.09.02 |
| XAI , cam, grad cam, lime, shap (0) | 2025.09.01 |
| AI 시스템 설계 (1) | 2025.09.01 |
| MoE (0) | 2025.08.31 |