CLIP은 최대 75토큰의 입력값을 받아서 가장 앞에 BOS(49406) 토큰을 넣고, 뒤에는 EOS(49407) 토큰으로 채운다
즉 '1girl'을 프롬프트로 넣으면 이것을 [49406, 272, 1611, 49407, 49407, 49407, ..., 49407] 토큰으로 변환된다. 또한 이미지 생성시 positive prompt 혹은 negative prompt가 75개 토큰을 초과할경우, 성능이 저하된다.
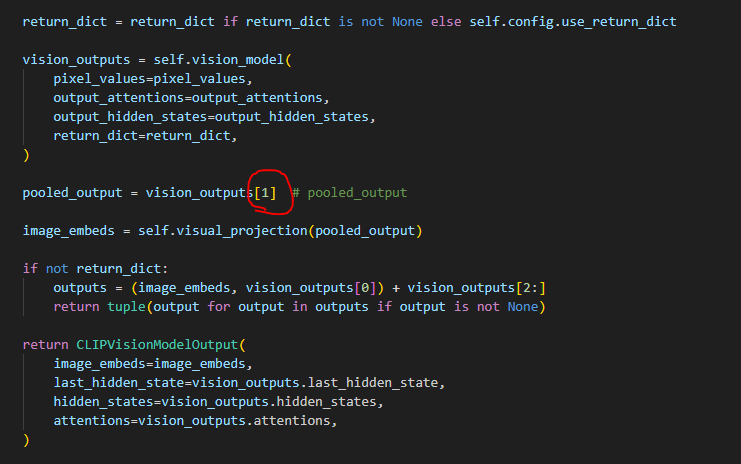
난 지금 vision transformer의 전체 결과물을(1개의 토큰을 뽑아낸게 아닌) visual_projection 한 결과물이 얻어야 한다.
즉, text embedding(77x768) 대신 vision_model(CLIPVisionTransformer)의 결과물을 visual_projection 시킨 결과물을 얻고자 한다. ( transformer에서 77은 바뀌여도 되지만, 768 은 바뀌면 안된다. )
그러면 코드는 아래와 같이 수정된다. last_hidden_state 전체를 뽑아내고, 전체를 projection visual_projection 한다.
last_hidden_state=vision_outputs.last_hidden_state # without pooling (custom) (b x 257 x 1024)
image_embeds=self.visual_projection(last_hidden_state) (b x 257 x 768)
text embedding ( 77x 768 ) 대신 image embedding(257 x 768 ) 을 쓰려고 할때,
batch x token은 달라도 되지만 , dimension은 같아야한다. 768 만 고정하면된다. !