
Mobilenet(Segmentation)
mobilenetv2 구조 설명:
MobileNetV2는 Depthwise separable convolution을 수정한 구조를 제안합니다.
제안된 Convolution Block은 Inverted Residuals와 Linear Bottlenecks를 사용하여 성능을 향상시킵니다.
relu구조상 입력 값이 채널수가 적은 ReLU 함수 계층을 거치면 정보가 손실됩니다.
반면에 입력 값이 채널수가 많은 ReLU 함수 계층을 거치면 정보가 보존됩니다
따라서 ReLU 함수를 사용할 때는 해당 레이어에 많은 채널 수를 사용하고, 해당 레이어에 채널 수가 적다면 선형 함수를 사용합니다.
Inverted Residuals와 Linear Bottleneck의 등장 배경임.

ViT 구조 : https://daebaq27.tistory.com/108
이미지를 패치단위로 쪼개 transformer의 입력으로 넣어주는 형태로 구성되어있습니다.
이때, 기존 transformer와 다른점은 패치단위로 나뉘면서 손실된 postion 정보를 보완하기위해 postion embeding을 취하고, classification이 가능하도록 class token을 삽입해 주는것이 기존 transformer와는 다릅니다.
class token, position 삽입하는 코드, position embeding에 sinusoidal이랑 learned 가 있을수 있음
그 임베딩하는 부분 코드
1)patch embeding
- 입력이미지 잘라다가 => 선현변환을 통해 패치 임베딩을 한다. 이때, 2차원 convolution을 이용해 구현가능
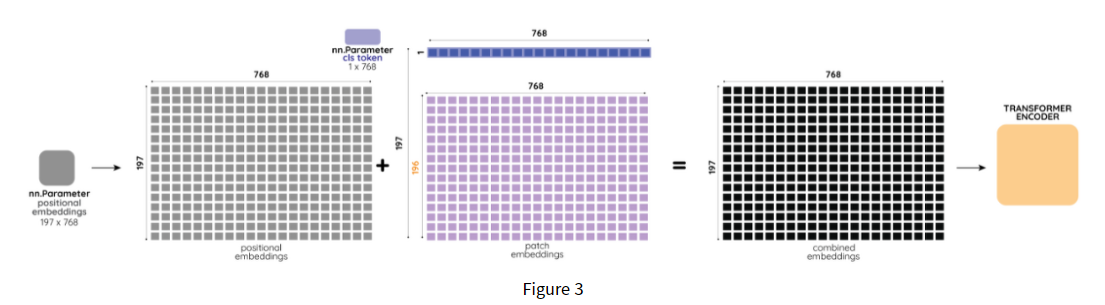
1,3,224,224 를 3*16*16*768으로 임베딩 시킴, 그 후 class token을 붙임.
그러면 (16*16+1 ) *768 *3 이되고, 이게 인코더에 들어가는 최종 텐서의 크기이다.
2) Positional Embeding (197*768)
원본이미지를 패치로 나누게되면, 이미지의 위치정보가 손실되는데, 이미지 상에서 위치정보는 매우 중요하다.
이에 각 patch에 대해 학습가능한 position embeddings를 추가하여 모델이 이미지의 구조를 학습할 수 있도록 함.
trainning시에 이에 관련된 정보를 학습하고, position embeddings에서 structrue정보를 인코딩해야한다.
중요포인트 :
class token과 positional 임베딩은 학습가능하다.
1) ViT가 inductive bias가 낮은이유 (추가적인 가정)
일반적으로 머신러닝 모델은 특정 데이터셋에 대해 더 좋은 성능을 얻고자 Inductive bias를 의도적으로 강제해준다.
예를들어 Vision 정보는 인접 픽셀간의 locality가 존재한다는 것을 미리 알고 있기 때문에 Conv는 인접 픽셀간의 정보를 추출하기 위한 목적으로 설계되어 Conv의 inductive bias가 local 영역에서 spatial 정보를 잘 뽑아낸다.
RNN은 순차적인(Sequential) 정보를 잘 처리하기 위해 설계되었다.
반면 Fully connected(MLP)는 all(input)-to-all (output) 관계로 모든 weight가 독립적이며 공유되지 않아 inductive bias가 매우 약하다.
Transformer는 attention을 통해 입력 데이터의 모든 요소간의 관계를 계산하므로 CNN보다는 Inductive Bias가 작다라고 할 수 있다. 따라서 Inductive Bias의 순서는 CNN > Transformer > Fully Connected 라고 예상할 수 있다.